Appearance
面对问题
现实背景
- GPT,Palm这样的大语言模型使得编程助理、聊天机器人等应用成为可能,同时他们也开始进入和影响我们的生活。许多云计算公司竞相提供该类应用程序。然而,目前运行这些程序的成本是昂贵的,需要大量的硬件加速器如GPU,考虑到这些情况,增加吞吐量,降低每次请求的成本便尤为重要。
- GPU计算能力的提升超过了其在内存上的提升,内存越来越成为一显著瓶颈。
理论背景
在NVIDIA A100使用 LLM时内存布局现实,大约65%内存分配给模型权重,该部分在服务期间保持静态,临时激活部分仅占用GPU内存的一小部分,故而管理KV cache 对服务器处理请求的能力至关重要。
KV(key value) cache原本作为牺牲空间换取运算速度的策略,但其具有一些问题:
- 占用内存高。在现有的内存分配策略中,为 KV cache 分配连续的物理内存。由于KV cache 动态的增大或缩小,分配连续的物理内存意味需预先分配一个具有可能最大长度的内存块,这导致了过度留存。由于在整个生命周期中保留了整个块,其他较短的请求不能占用当前块中未使用的任何部分,产生了内部碎片,同时由于每个请求预分配大小的不同,可能产生较大的外部碎片,造成内存浪费。
- 由于 KV cache 大小取决于序列长度,具有高度可变和不可预测的特点,因而难以高效管理。
- 由于序列的 KV cache 存储在独立的连续空间中,现有的 KV cache 管理方法无法实现内存共享,而很多高级解码算法,例如并行采样使得单个请求产生多个输出,这产生的多个序列部分共享他们的 KV cache 的需求。
主要成果
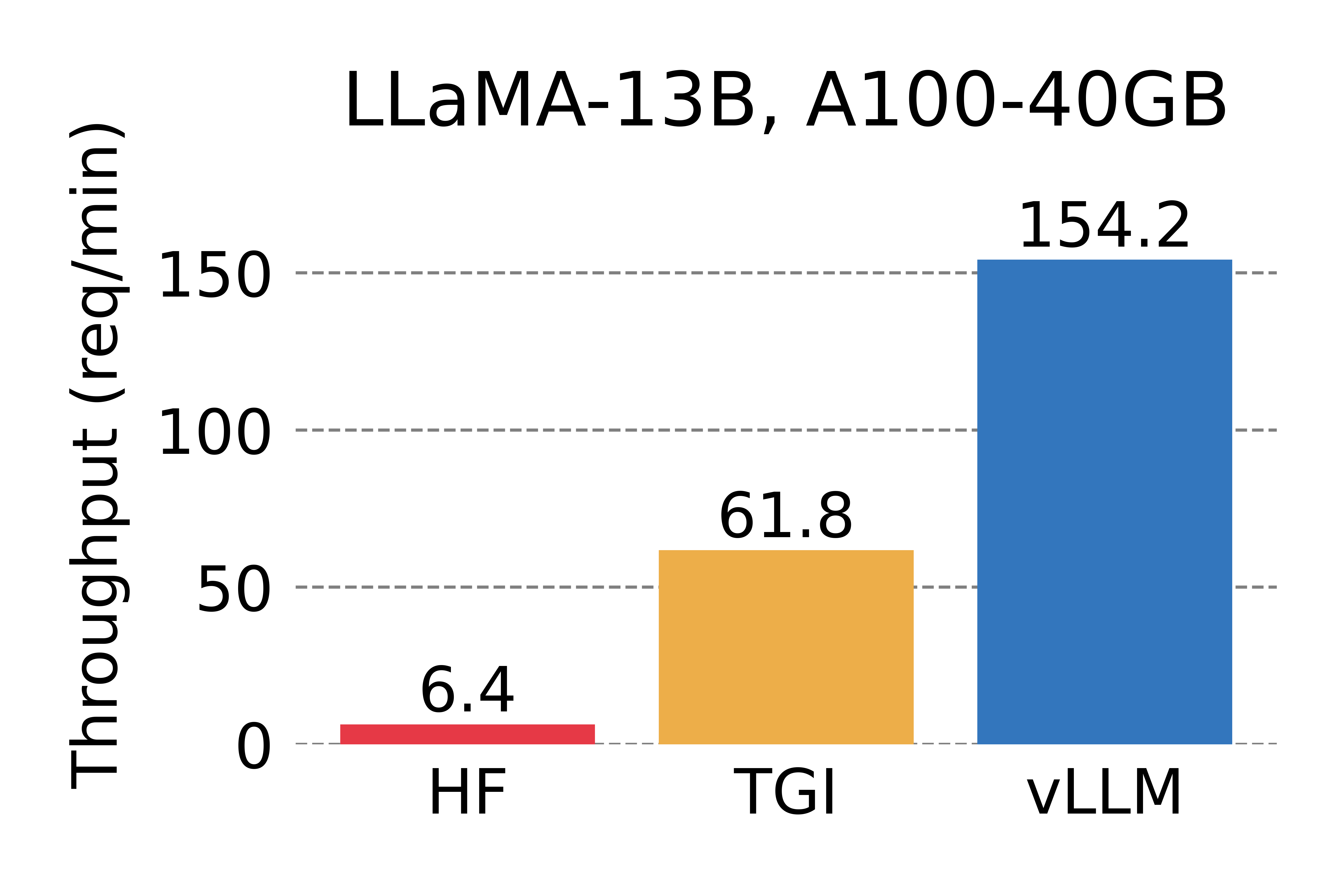
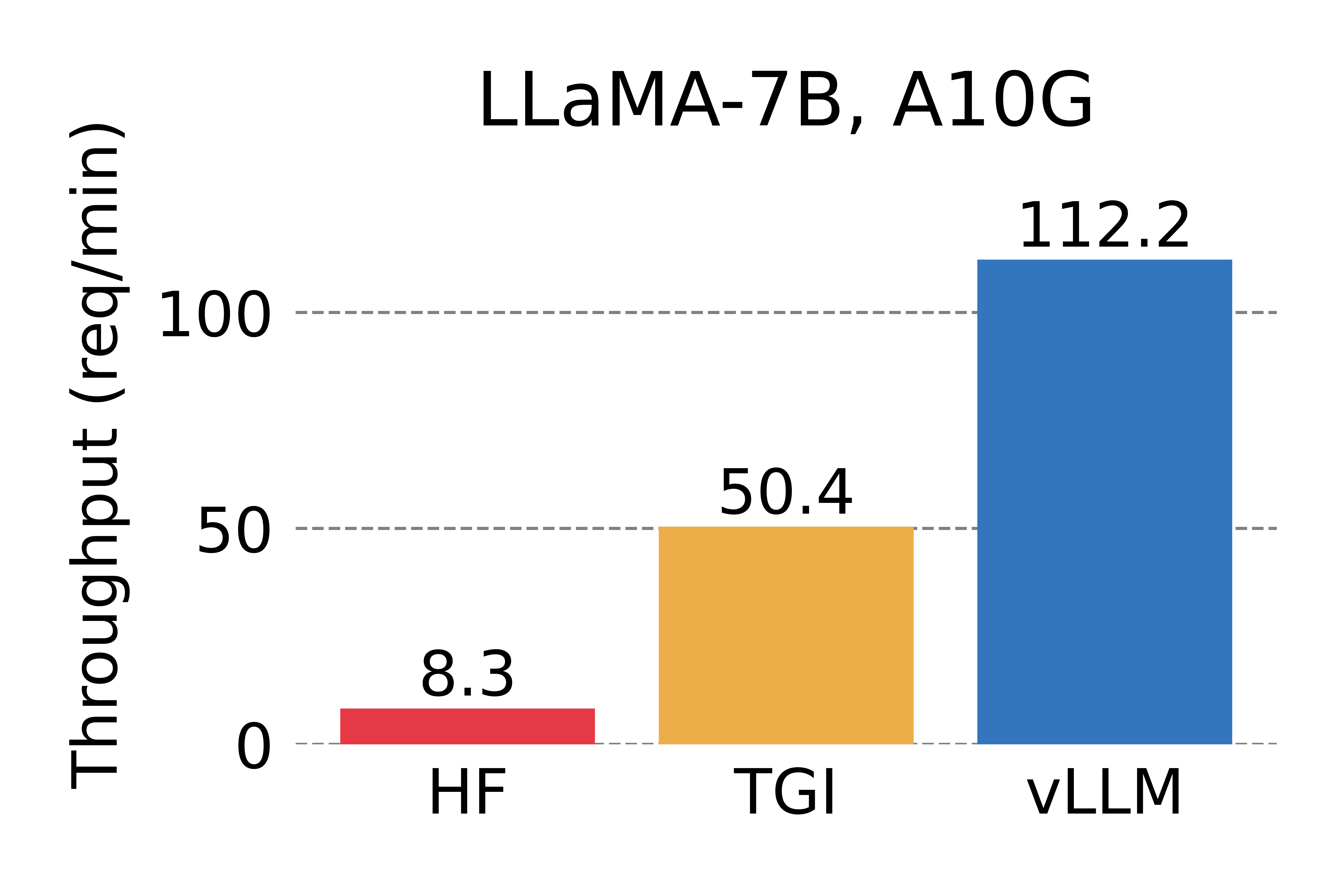
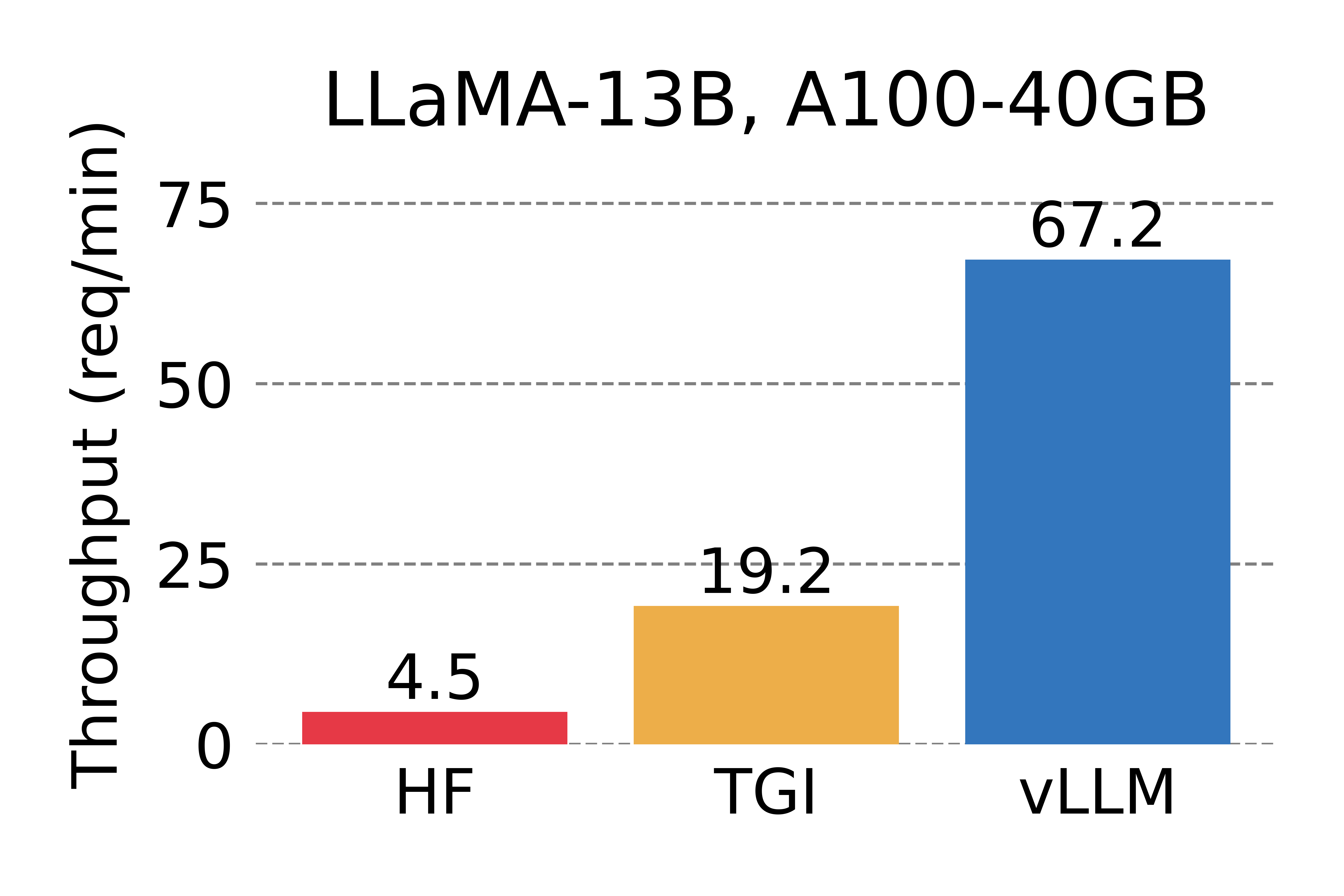
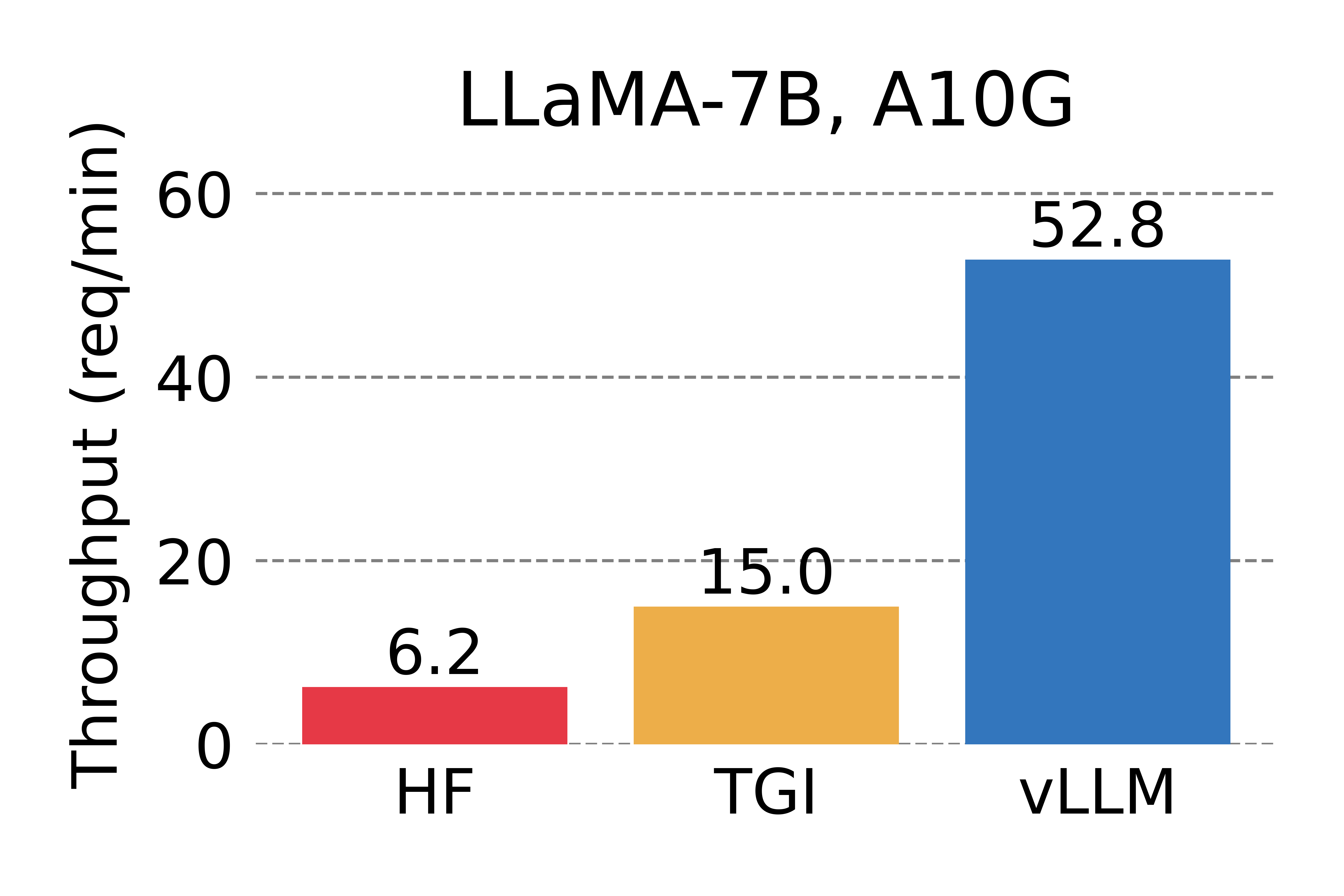
- 确定了LLM时内存分配的挑战,并量化了其对LLM性能的影响-Fig.1
- 受OS中虚拟内存和分页的启发,提出了将 KV cache 存储于非连续分页内存中的方法PagedAttention。
- 设计
vLLM,一个建立在PagedAttn上的LLM服务引擎。 - 评估了各种情况下
vLLM的表现,并证实其确实大大优于先前最先进的解决方案-Fig.12Fig.18
PagedAttention
以下几个动图能够帮助快速理解主要思想。
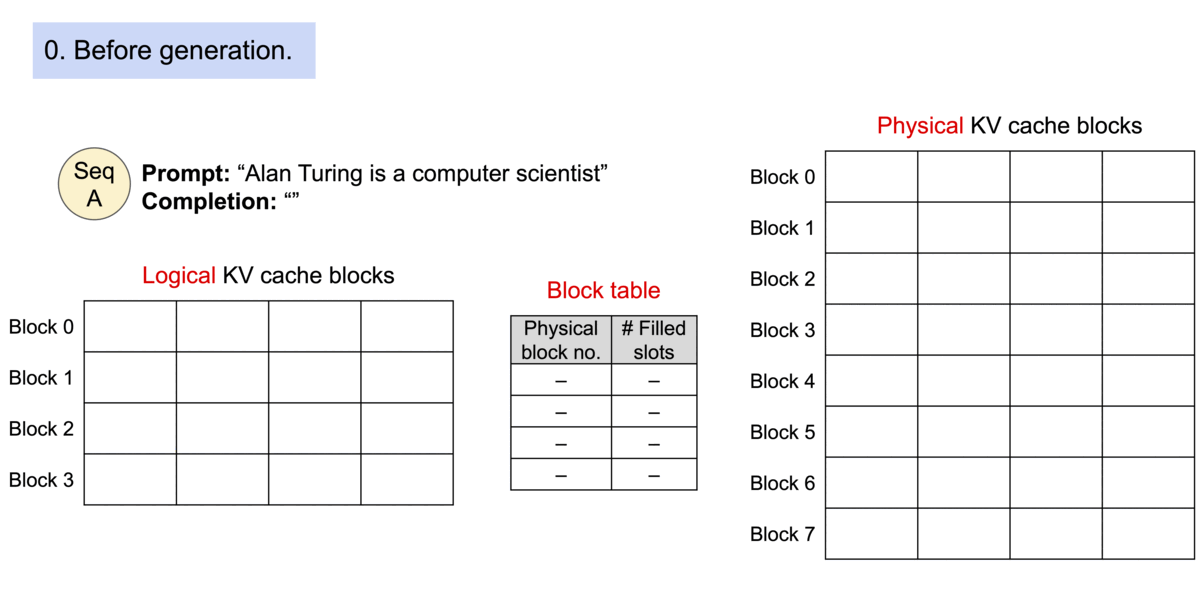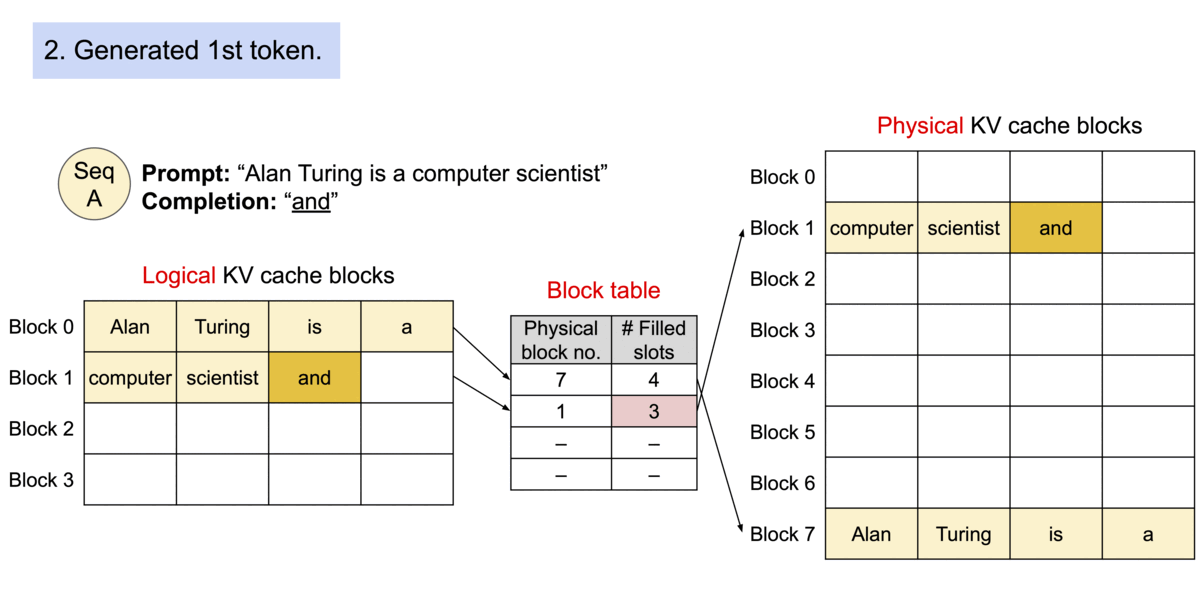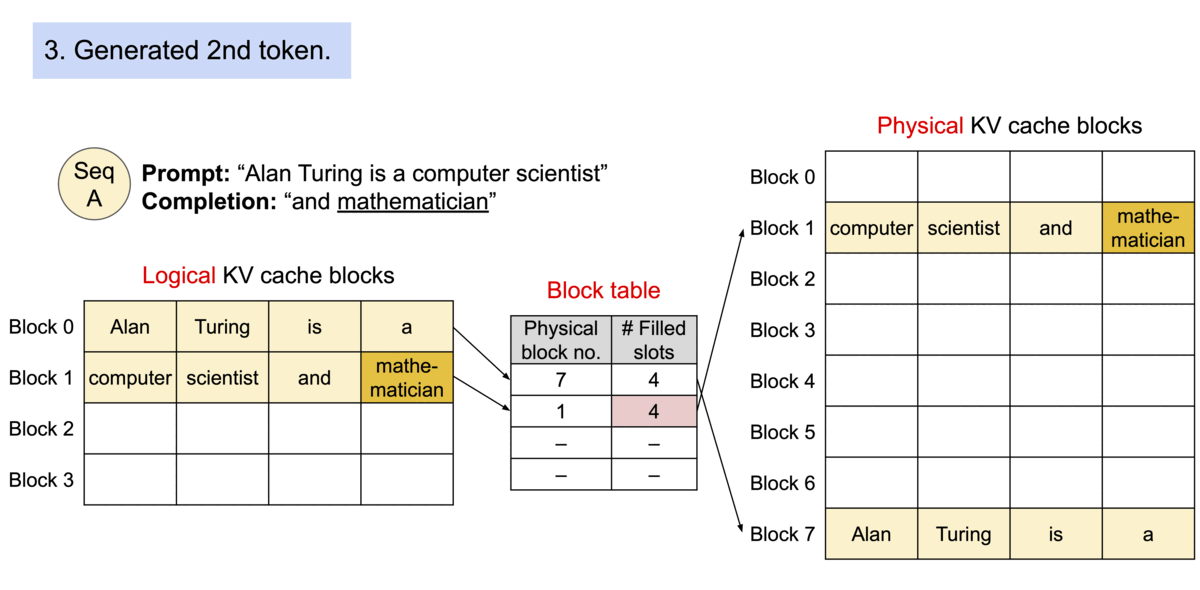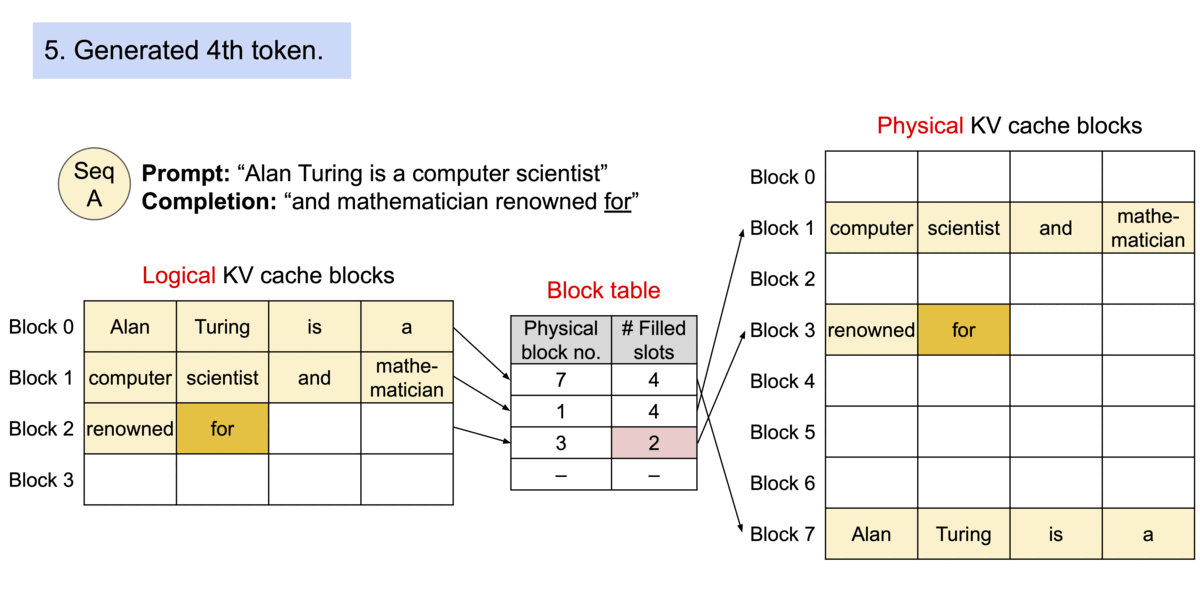
- 以不连续的块存储连续的键值,整个思想参考os的虚拟内存,使用连续的逻辑页映射到非连续的物理内存,当用户通过程序访问物理内存时,感知到的如连续分配下相同。具体的,预先将 KV cache 设置为大小固定的块,采用动态分配的策略,在新请下分配一个连续的物理KV块并从左到右依次填充,同时额外维护一个块表,用以记录一个逻辑块对应的物理块的位置和填充的数量,当前请求下直至块满才分配新块。如动图所示,这显然减少了内部资源的浪费(单次请求至多浪费一个块的大小)。
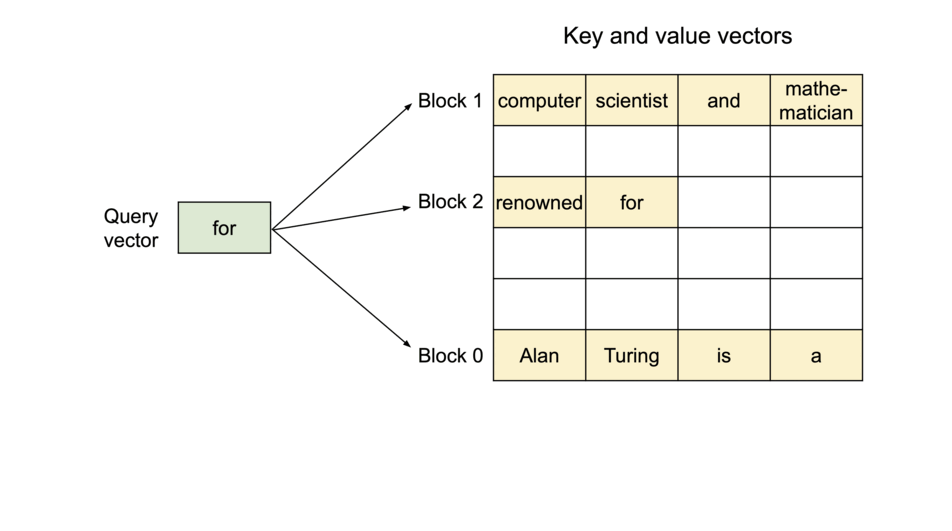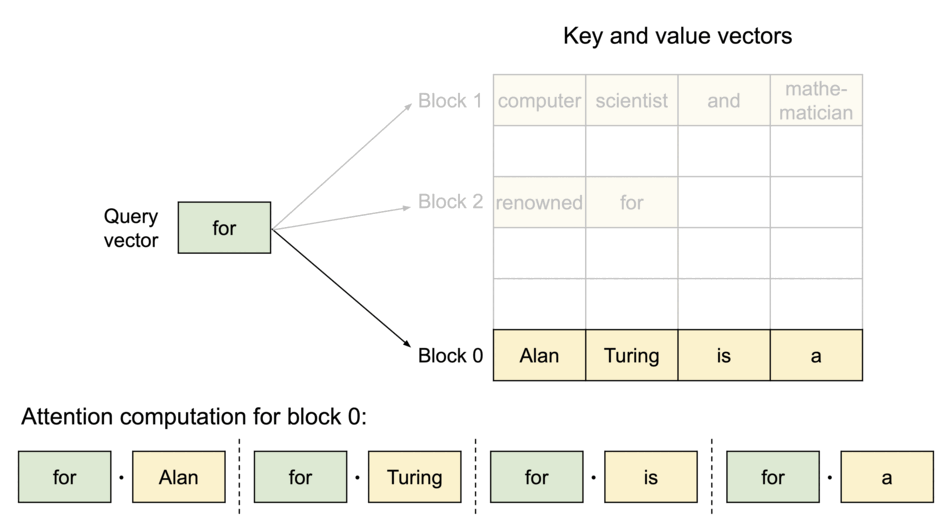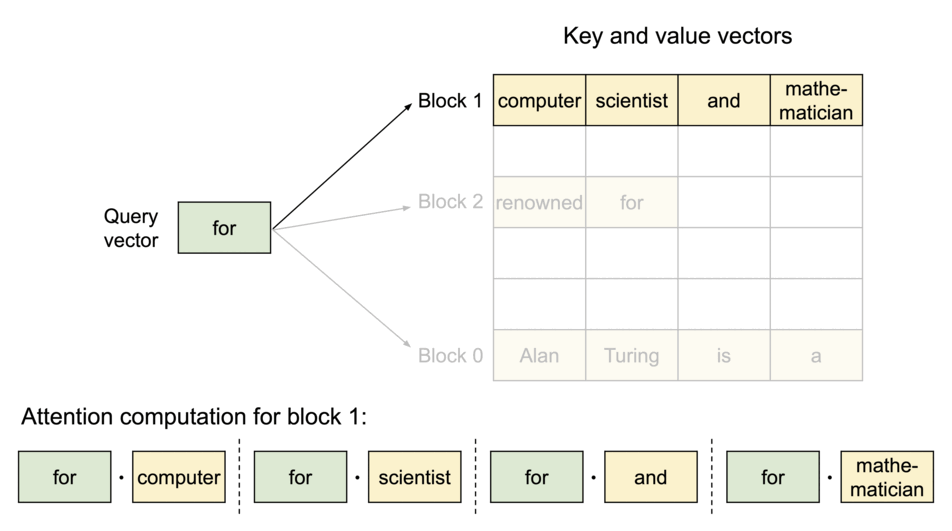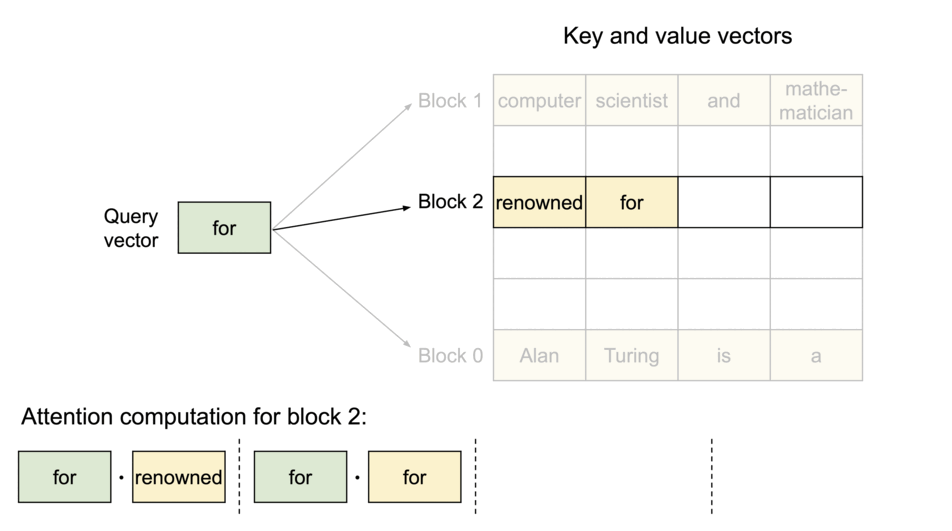
- 块表的翻译
- 内存共享方面,以并行取样为例。在并行采样中,一个请求产生多个序列,从而多个序列中包含有多个相同的提示文本,图示为两个输出并行解码的示例,由于两个输出共享一个提示符,在最初阶段只需要为该提示符提供一个副本空间,两个序列的逻辑块被映射到相同的物理块中,由于每个物理块可被多次映射,故增添一个引用计数器,当识别到该块引用计数
,则执行写时复制操作,分配新的物理块并复制原物理块的信息,并将引用计数减少1,如动图所示。 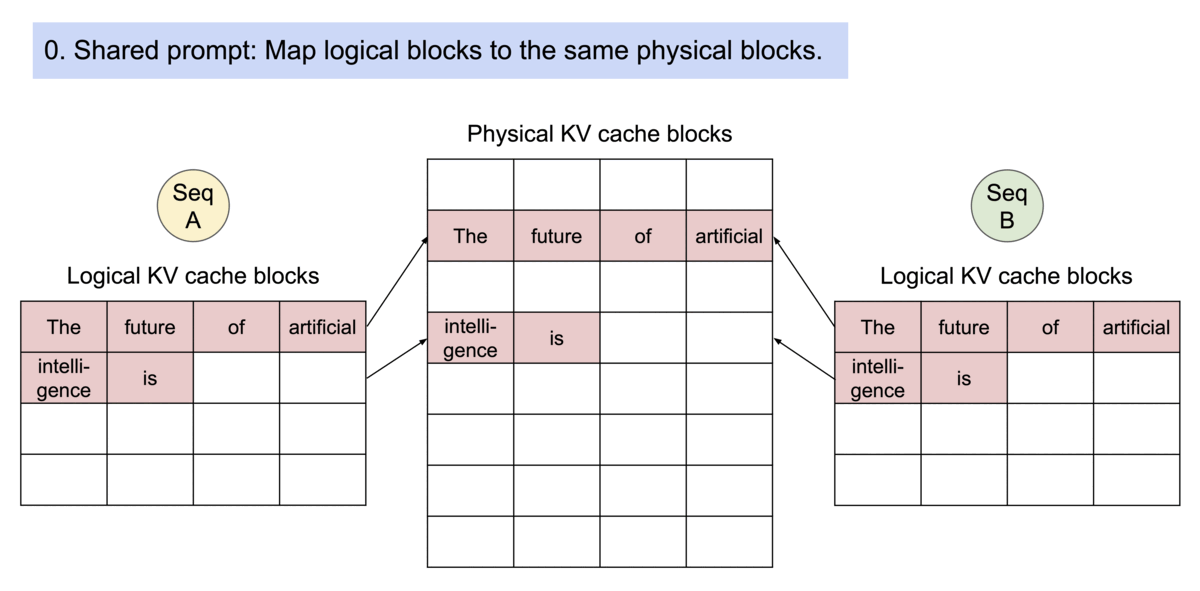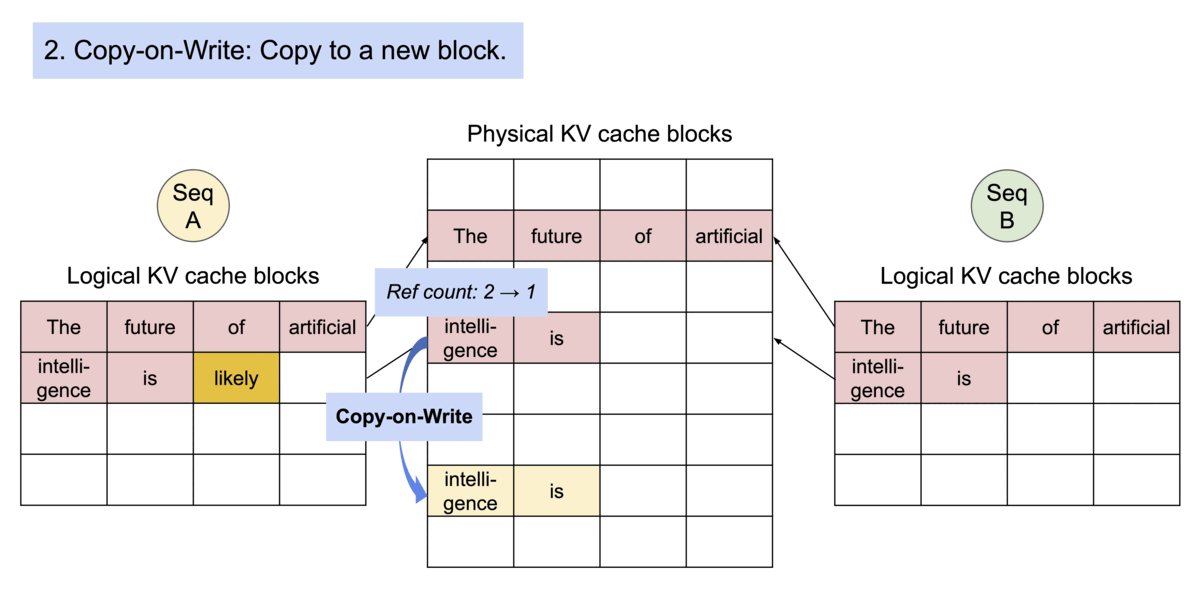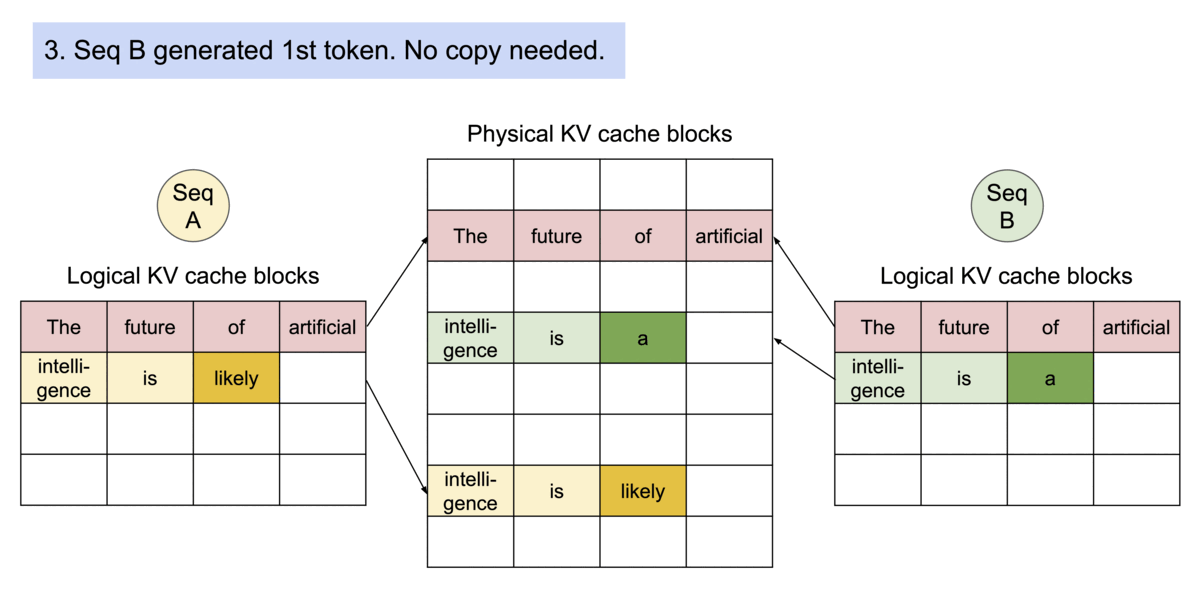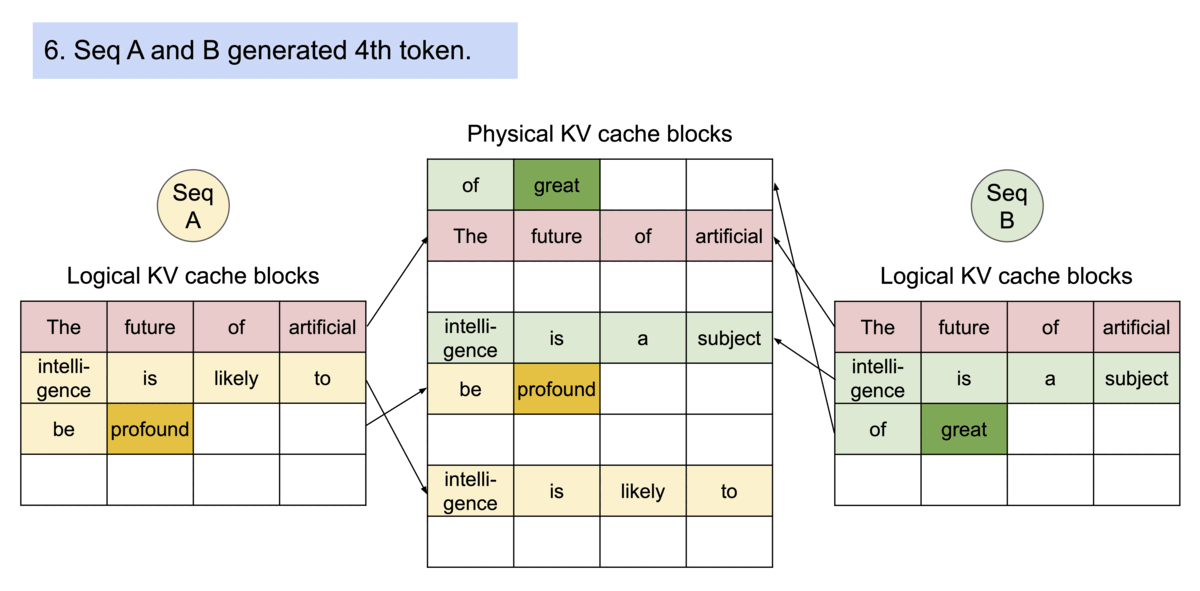
- 块大小的设置
这里作为简单的叙述。显然块不能太大,不然序列比块短,则无法共享(每次都要copy-on-write)并且还会产生较大的内部碎片,同时不能太小,太小vLLM无法充分利用GPU并行性来读取和处理 KV cache。综合考虑,默认16。