Appearance
概要
- Transfomer
- 计算复杂度高
- 无法利用复杂的图结构
- GNN
- 固定的结构,WL限制
- 弱的表达能力
针对GNN方面,在传统的MP模型中,下面左右两种图结构无法得到区分 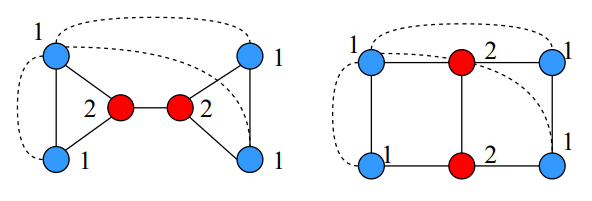
模型
数据预处理
注意力采样机制
作用:扩充了感知范围,使得采样不再局限于邻居
式(1)为自注意力表达式,左端
式(2)相当于对中心点
TIP
复杂度显然是
位置编码
图结构是不存在天然的节点序列的,为此本文考虑位置编码与以下三个方面有关
- 最短hop-path
- degree
- PageRank embedding
TIP
在这里是有疑问的,很多节点的特征例如介数中心性都能够作为学习位置编码的输入信息,Rethinking Graph Transformers with Spectral Attention一文或许给出的位置编码学习方式更可信
对于中心点
TIP
复杂度与最短路算法复杂度有关,在堆数据结构下可进一步优化。
模型架构
Transormer Layer
首先是Transformer层,旨在扩充GNN感知范围使其能够聚合多hop以外的相关节点的信息。
但直接将其应用到整个图上会
- 无视连通性在整个图上传递信息
- 计算复杂度 本文做了如下改进,以
为中心点为例
TIP
矩阵运算下具有复杂度
上式中
GNN
作用:捕捉邻居信息,更好的利用图结构。
TIP
计算复杂度仍然为
Samples Update Sub-Module
作用:在Trans 和 GNN layers后, S应该得到更新。但重新计算所需要的时间成本昂贵。
本文提出了两种解决方案
Random Walk based Update
设计转移概率
通过控制随机Walk的长度
Message Passing based Update
对中心点
理论
- TransGNN 至少与 GNN 持平 通过控制
,可以使得 - TransGNN 比 1-WL 更有表现力 若感知视野为1,下图中左右图无法区分,至少TransGNN中利用最短路信息不同,故而是可分辨的