Appearance
参考FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness。
03-16更新:对思路、原理进行详细的展开描述。
面临问题
Transformer 框架由于核心组件self-attention对耗时及内存占用上都是序列长度FlashAttn使得Transformer能够建模长序列,这带来以下几个好处:
- 扩展功能: 使得NLP不仅能够处理段落,同时可以理解书籍、说明书等。
- 逼近现实: 例如CV上更高的分辨率意味着更好、更强的洞察力
- 开拓新领域: audio.video,medical imaging data
GPU
TIP
补充GPU工作原理
计算过程中,首先将HBM中的数据加载和写入到SRAM中,在SRAM中完成计算将数据传回并写入HBM。这里SRAM理解为L1 cache和shared memory即可。
贡献
- 节省显存:减少了额外数据的存储消耗。
- 精准注意力:在使用稀疏计算时,能够保证结果的准确性。(未更新)
- 设计计算块:Tilling, extra statistics, combine the results。
思路
- 尽量使用SRAM,单次传输占满
分块计算 - 减少内存搬运次数
融合计算
Forward
Attn 横向对比
对比标准Attn,Flash Attn在前向传播中使用
标准Attn

可以看到,在整个过程中,对SRAM
- 读入: Q, K, S, P, V
- 写出: S, P, O
- 数据搬运量:
, - 额外内存消耗:
- 运算复杂度:
Flash Attn

- 读入:
- 外循环: K, V
- 内循环:每次内循环读入一个完整的Q,为
- 写出:O, m, l
- 数据搬运量:
- 额外内存消耗:
- 运算复杂度:
主要思路
主要原则:充分利用SRAM高速计算能力,保证每次数据传输能够填满SRAM。根据SRAM-size(假定为
事实上,观察Algorithm1可以发现,SRAM中常驻的变量为SRAM的内存大小SRAM的内存空间,实现高速计算。
分块计算面临问题
- 例如,假设
, , 则根据 得到 。
由于softmax需对整行数据执行操作,此时,分块后的每次循环中,不完全的input(真正的并行发生在串接concatenated上)对softmax操作带来了挑战。 ,显然 对 有依赖,标准情况下需要待 计算完成后返回到 HBM后重载求解,这导致了额外的显存消耗和数据传输。
问题解决
Safe-softmax
当数据值很大时,对于FP-16数据类型,safe-softmax,对于
考虑对1,2进行融合,使得2步
注意:这部分对应算法的第10到11行。
O = PV
由于最终需要的结果为softmax一样改为递推式,使得每一个循环产生的SRAM中完成对
考虑在外循环为SRAM中得到的数据有
则
注意:
- (5)到(6):凑
- (6)到(7):上式包含
,计算过程绕不开 ,故使用 替代,使得 可被释放。 - 这部分对应算法第12行
Backward
如果不清楚基本的标量对向量,softmax求导,请参考这两篇文章CSDN, blog。
横向对比
可以看到,在Backward过程,FlashAttn减少了数据搬运,增加了计算量(重计算),由于此时主要为Mem-bound,故有利于性能提升。
标准 Attn

- HBM:Q, K, V, O, S, P
- 读入:P,dO,V,P,dP,dS,K,dS,Q
- 写出:dV,dP,dS,dQ,dK
Flash Attn

- HBM:m,l,Q,K,V,O,dO
- 重计算:对应算法11到15行。
这里采用重计算的方式,即不直接搬运,而是在反向传递过程中,经由 得到 后结合 得到 。
Backward 过程分块梯度传递
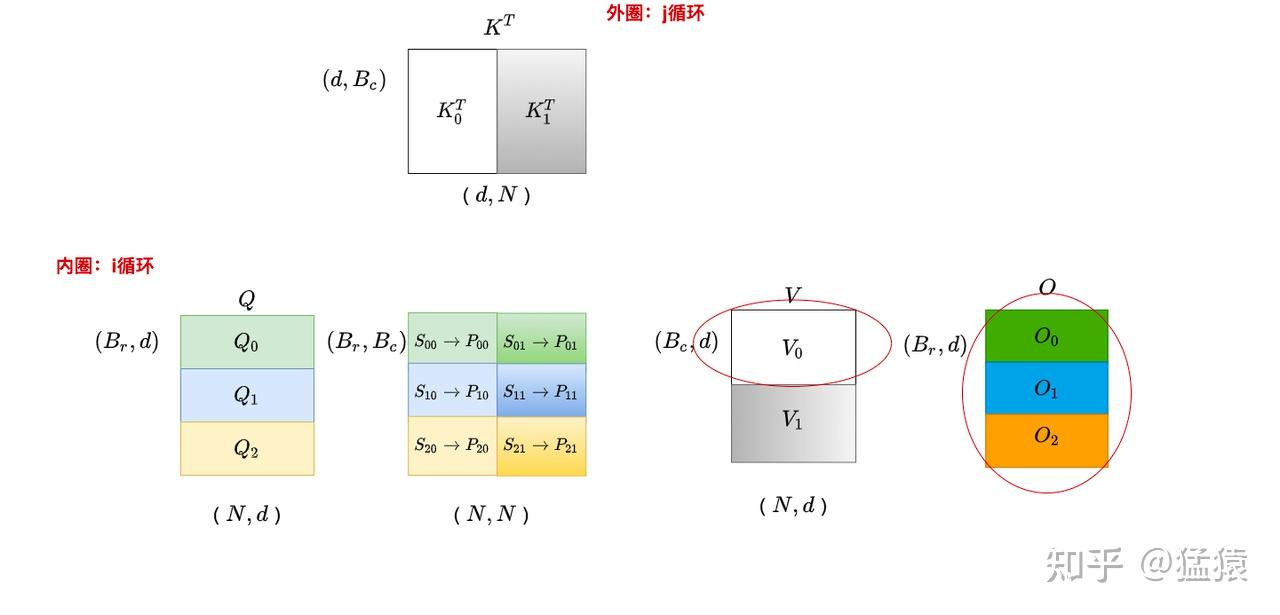
- V:对应算法16行
当外循环为0时,与 相乘得到 。则 ,进而
- P:对应算法17到18行
对于,在外循环为 时仅与 有关,内循环为 与 有关
- S:对应算法19到20行
- 第一个等式为对softmax求导
- 修改为点乘是为了扩展到块(多行) 设
为 的某一行,注意,不表示分块。
则最终
- Q:对应算法21行
, 对于 ,他与 有关,与 有关。则
- K:对应算法22行 对于外循环
, 与 有关,与 有关,则
实验成果
Speed up
- Fig2: 对比传统的
Attn,尽管FlashAttn在增加计算(如后向传播中的重新计算),但HBM的读写仅为传统方法的,速度上提升了6倍。 - E.5: 在不同的GPU下,不同的组件(是否含有Mask,Dropout),不同序列长度的所有情况下,
FlashAttention较基准情况加速倍。 - 4.1 BERT: 达到一定精度所需要的训练时间更短。比创下Nvida记录的MLPerf 1.1 加速了15%。
- GPT-2: 在GPT-2 small 和 GPT-2 midium 数据集上与Huggingface 和 Megatron-LM 对比,保持同等精度且速度较Huggingface为
。
Longer Sequences
- 4.2 LM with Long Context: 通常增长上下文的长度后训练速度会变慢但可以得到一个更好的模型(Table 5 展示了在更长的上下文训练的模型具备更高的分类精度)。列表展示了
FlashAttn在文本长度的情况下具备比 文本长度下 Megatron-LM更快的训练速度,更长的序列代表模型更高的质量。 - 第一个解决
Path-X的Transformer。