Appearance
入门(with C++)
参考Nvida-zh了解支持CUDA的Nvida GPU型号。
Hello World
核函数使用__global__进行修饰,其返回类型必须是void类型。在核函数中可以使用return关键字但不会返回任何值。核函数无法成为一个类的成员,通常情况下,使用一个包装函数对核函数进行调用,将包装函数定义为类的成员。
cpp
#include <stdio.h>
__global__ void hello_world2gpu(){
printf("Hello world, from GPU.\n"); //nvcc不支持cout<<方式输出
}
int main(void){
hello_world2gpu<<<1,1>>>(); // <<<grid_size,block_size>>>配置线程 线程块数量-单个块线程数量
cudaDeviceSynchronize(); // 同步函数
return 0;
}zsh
nvcc Hello2thread.cu -o Ex1 -arch=compute_61 -code=sm_80-arch=compute_xx指定虚拟架构,-code=sm_xx指定真实计算能力,实践中保持兼容性的条件下,虚拟架构尽可能小,真实架构尽可能大。
同时,为保证兼容性,可以指定多组计算能力,例如
zsh
nvcc Hello2thread.cu -o Ex2_fat -gencode arch=compute_50,code=sm_50 -gencode arch=compute_60,code=sm_60 -gencode arch=compute_70,code=sm_70 -gencode arch=compute_80,code=sm_80生成的可执行文件称为胖二进制文件,注意过多制定计算能力会增加编译时间和可执行文件的大小。
TIP
注意网格与线程块大小具有限制,通常,网格大小在
NVCC即时编译
参考知乎
大概用于在当前架构下生成更前向的虚拟架构的PTX代码,此时指定的两个计算能力都是虚拟架构的计算能力,且必须一致,例如: 若本人GPU不支持80架构
zsh
nvcc Hello2thread.cu -o Ex2_fat -gencode arch=compute_50,code=sm_50 -gencode arch=compute_60,code=sm_60 -gencode arch=compute_70,code=sm_70 -gencode arch=compute_80,code=compute_80CUDA矩阵加法
代码参考github
CUDA程序框架
- 设置GPU
cpp
#include <stdio.h> // 头文件
int main(void){
int iDeviceCount=0;
cudaError_t cudaStatus = cudaGetDeviceCount(&iDeviceCount); // 获取GPU数量,成功返回cudaSuccess
if (cudaStatus != cudaSuccess || iDeviceCount == 0){
printf("No CUDA camptable GPU found! \n");
exit(-1);
}
else{
printf("The count of GPUs is %d. \n",iDeviceCount);
}
int iDev = 0;
cudaStatus = cudaSetDevice(iDev); // host 设置GPU
if (cudaStatus != cudaSuccess){
printf("Fail to set GPU %d for computing. \n",iDev);
exit(-1);
}
else{
printf("Set GPU successfully. \n");
}
return 0;
}内存管理
参考菜鸟教程
自定义设备函数
- 设备函数使用
__device__修饰 - 核函数使用
__global__函数修饰,一般由主机调用,设备执行。(也存在核函数中调用核函数的现象,此时由设备调用) __global__不能和__host__,__device__同时使用。- 主机函数使用
__host__修饰,对于主机端的函数,该修饰符可省略。 - 若函数需在主机和设备中运行,可使用
__host__,__device__同时修饰该函数,此时编译器会针对主机和设备分别编译该函数,减少冗余代码。
CUDA错误检查
CUDA错误会发生在两个阶段——编译时错误,运行时错误。编译时发生错误编译器会将错误所在位置进行返回。
Runtime API 错误
错误检查函数
cudaGetErrorName: 获取错误代码对应的错误名称,返回 char *类型cudaGetErrorString: 获取错误代码的描述信息,返回char *类型
cpp
#include <stdio.h>
cudaError_t ErrorCheck(cudaError_t error_code, const char* filename, int linenum){
if (error_code != cudaSuccess){
printf("Cuda_Error:\ncode:%d, name:%s, description:%s\n file:%s, line:%d\n ",
error_code,cudaGetErrorName(error_code),cudaGetErrorString(error_code),filename,linenum);
}
return error_code;
}检查核函数
错误检查函数无法捕捉调用核函数相关错误,由于__global__ void,核函数不会返回错误值,可使用如下代码捕捉核函数中的可能错误。
c++
ErrorCheck(cudaGetLastError(),__FILE__,__LINE__);// 返回上一条cuda_Error
ErrorCheck(cudaDeviceSynchronize(),__FILE__,__LINE__); //由于CPU与GPU异步,需在此加入一个同步函数,等待核函数运行完成。CUDA记时
事件记时
程序执行时间计时,是CUDA程序执行性能的重要表现,使用事件记时方式。框架如下
c++
cudaEvent_t start, stop; // 定义用来记时的CUDA事件变量
ErrorCheck(cudaEventCreate(&start), __FILE__, __LINE__); //初始化事件
ErrorCheck(cudaEventCreate(&stop), __FILE__, __LINE__);
ErrorCheck(cudaEventRecord(start), __FILE__, __LINE__); // 记录代表时间开始的事件
cudaEventQuery(start); //此处不可用错误检测函数,cudaErrorNotReady
addFromGPU<<<grid, block>>>(fpDevice_A, fpDevice_B, fpDevice_C, iElemCount); // 核函数,需要记时的代码
ErrorCheck(cudaEventRecord(stop), __FILE__, __LINE__); // 记录代表时间结束的事件
ErrorCheck(cudaEventSynchronize(stop), __FILE__, __LINE__);
float elapsed_time;
ErrorCheck(cudaEventElapsedTime(&elapsed_time, start, stop), __FILE__, __LINE__); //计算两个work间的elapsed time
// printf("Time = %g ms.\n", elapsed_time);
if (repeat > 0) // 不计入第0次的情况,这是由于第一次调用核函数往往时间更多
{
t_sum += elapsed_time;
}
ErrorCheck(cudaEventDestroy(start), __FILE__, __LINE__); // 销毁前面定义的时间类型变量
ErrorCheck(cudaEventDestroy(stop), __FILE__, __LINE__);nvprof 性能刨析工具
nvprof是一个可执行文件,执行方式为: nvprof ./exe_name。
TIP
目前较新的GPU可能不再支持nvprof,可替换为Nsight System,Arch系统下包含在cuda-tools包中,执行nsys进行分析。
运行时GPU信息的查询
查询熟知自身GPU性各项能才能高效进行CUDA程序开发,参考Nvida doc
GPU性能评价指标
- 浮点数运算峰值,FLOPS
- GPU内存、带宽。
运行时API查询GPU信息
GPU硬件知识参考知乎,prop结构体中包含的信息参考Nvida
c++
int device_id = 0; // 设置设备ID
ErrorCheck(cudaSetDevice(device_id), __FILE__, __LINE__); // 设置使用的GPU
cudaDeviceProp prop; // 结构体,存储GPU相关属性
ErrorCheck(cudaGetDeviceProperties(&prop, device_id), __FILE__, __LINE__);查询GPU计算核心数量
无运行时API可直接查询,根据其主版本号,次版本号及SM数量,使用下面函数可计算
c++
#include <stdio.h>
#include "./tools/setDevice.cuh"
int getSPcores(cudaDeviceProp devProp)
{
int cores = 0;
int mp = devProp.multiProcessorCount;
switch (devProp.major){
case 2: // Fermi
if (devProp.minor == 1) cores = mp * 48;
else cores = mp * 32;
break;
case 3: // Kepler
cores = mp * 192;
break;
case 5: // Maxwell
cores = mp * 128;
break;
case 6: // Pascal
if ((devProp.minor == 1) || (devProp.minor == 2)) cores = mp * 128;
else if (devProp.minor == 0) cores = mp * 64;
else printf("Unknown device type\n");
break;
case 7: // Volta and Turing
if ((devProp.minor == 0) || (devProp.minor == 5)) cores = mp * 64;
else printf("Unknown device type\n");
break;
case 8: // Ampere
if (devProp.minor == 0) cores = mp * 64;
else if (devProp.minor == 6) cores = mp * 128;
else if (devProp.minor == 9) cores = mp * 128; // ada lovelace
else printf("Unknown device type\n");
break;
case 9: // Hopper
if (devProp.minor == 0) cores = mp * 128;
else printf("Unknown device type\n");
break;
default:
printf("Unknown device type\n");
break;
}
return cores;
}
int main()
{
int device_id = 0;
ErrorCheck(cudaSetDevice(device_id), __FILE__, __LINE__);
cudaDeviceProp prop;
ErrorCheck(cudaGetDeviceProperties(&prop, device_id), __FILE__, __LINE__);
printf("Compute cores is %d.\n", getSPcores(prop));
return 0;
}组织线程模型
数据在内存中以线性,以行为主的方式存储。发挥GPU中多线程的优点,就是要让每个线程处理不同的数据运算,必须合理的组织线程,避免多个线程处理同一数据或胡乱访问内存的情况出现。
二维网格二维线程块
ix = threadIdx.x + blockIdx.x*blockDim.x;
iy = threadIdx.y + blockIdx.y+blockDim.y;
idx = iy*nx + ix;二维网格一维线程块
ix = threadIdx.x + blockIdx.x * blockDim.x;
iy = blockIdx.y;
idx = iy * nx + ix;一维网格一维线程块
此时无法做到每个线程对应矩阵中一个元素,需要循环执行。
c++
__global__ void addMatrix(int *A, int *B, int *C, const int nx, const int ny)
{
int ix = threadIdx.x + blockIdx.x * blockDim.x; // 此时iy 由循环执行决定
for (int iy = 0; iy < ny; iy++)
{
int idx = iy * nx + ix;
C[idx] = A[idx] + B[idx];
}
}全局内存
对全局内存的访问将触发内存事务,也就是数据传输。在线程访问内存引发数据传输的过程中,传输的数据有的是线程所需要的,而有的是额外数据,对他们的传输产生了资源浪费,使用合并度对资源利用率进行衡量。
合并与非合并访问
合并度等于线程束请求的字节数除以由该请求导致的数据传输处理的全部数据的字节数。当合并度为100%也就是说线程数对全局内存的一次访问请求导致了最少的数据传输,我们称该访问为合并访问,否则为非合并的。
要分析一个访问是合并的还是非合并的,首先要明晰数据传对数据地址的要求(这里考虑全局内存的读取仅使用
TIP
CUDA运行时API cudaMalloc()分配内存的首地址至少为256字节的整数倍。
c++
// 合并访问
void __global__ add(float *x, float *y, float *z){
int n = threadIdx.x + blockIdx.x*blockDim.x;
z[n] = x[n] + y[n];
}
add<<<128,32>>>(x,y,z)可以看到,核函数中对这几个指针的访问都是合并的。例如,在第一个线程块中的线程束将访问数组中的0到31个数据,对应着0到127字节的连续内存,是合并访问。
c++
// 非合并访问
void __global__ add(float *x, float *y, float *z){
int n = blockIdx.x + threadIdx.x*gridDim.x;
z[n] = x[n] + y[n];
}
add<<<128,32>>>(x,y,z)如上,第一个线程块中的线程束将对数组中第0, 128, 256...元素进行访问,都不在同一个连续32字节的内存片段中,故需要访问32次,此时合并率为
矩阵转置(例)
下面为完整的矩阵转置的例子,代码中首先生成了一个给定大小的随机方阵,之后进行了转置并对核函数进行记时。值得一提的是,在两种核函数中都包含了一个合并访问和一个非合并访问,但其执行速度却不同。这是因为,如果编译器判断一个全局变量在整个核函数范围内只可读,则会自动使用__ldg()函数对数据的读取进行缓存,从而环节非合并访问带来的影响。而在写入操作是没有类似的函数可以调用的。
c++
#include <stdio.h>
#include "./tools/setDevice.cuh"
// 设计核函数
__global__ void transpose1(const float *A,float *B, const int N){
const int nx = threadIdx.x + blockDim.x*blockIdx.x;
const int ny = threadIdx.y + blockDim.y*blockIdx.y;
if (nx < N && ny< N){
B[nx*N + ny] = A[ny*N+nx]; // 此时对于A的内存访问为合并的,即读合并,写非合并。
}
}
__global__ void transpose2(const float *A, float *B, const int N){
const int nx = threadIdx.x + blockDim.x*blockIdx.x;
const int ny = threadIdx.y + blockDim.y*blockIdx.y;
if (nx < N && ny< N){
B[ny*N + nx] = __ldg(&A[nx*N+ny]); // 此时对于B的内存访问为合并的,即写合并,读非合并。
}
}
void initialData(float *addr, int elemCount)
{
for (int i = 0; i < elemCount; i++)
{
addr[i] = (float)(rand() & 0xFF) / 10.f; // 做逻辑与操作,限制随机数不超过255/10
}
return;
}
int main(void){
SetGPU(); // 设置GPU
const int N = 128; // 设置矩阵大小
int iElemCount = N*N; // 设置元素数量
size_t stBytesCount = iElemCount * sizeof(float); // 字节数
// 分配主机内存
float *fpHost_A, *fpHost_B;
fpHost_A = (float *)malloc(stBytesCount); // 分配动态内存
fpHost_B = (float *)malloc(stBytesCount);
if (fpHost_A != NULL && fpHost_B != NULL)
{
memset(fpHost_A, 0, stBytesCount); // 主机内存初始化为0
memset(fpHost_B, 0, stBytesCount);
}
else
{
printf("Fail to allocate host memory!\n");
exit(-1);
}
float *fpDevice_A, *fpDevice_B;
ErrorCheck(cudaMalloc((float**)&fpDevice_A, stBytesCount), __FILE__, __LINE__);
ErrorCheck(cudaMalloc((float**)&fpDevice_B, stBytesCount), __FILE__, __LINE__);
if (fpDevice_A != NULL && fpDevice_B != NULL){
ErrorCheck(cudaMemset(fpDevice_A, 0, stBytesCount), __FILE__, __LINE__); // 设备内存初始化为0
ErrorCheck(cudaMemset(fpDevice_B, 0, stBytesCount), __FILE__, __LINE__);
}
else{
printf("fail to allocate memory\n");
free(fpHost_A); // 释放先前CPU中制定的内存
free(fpHost_B);
exit(-1);
}
// 初始化主机中数据
srand(666); // 设置随机种子
initialData(fpHost_A, iElemCount);
// 主机复制到设备
ErrorCheck(cudaMemcpy(fpDevice_A,fpHost_A,stBytesCount,cudaMemcpyHostToDevice),__FILE__,__LINE__);
ErrorCheck(cudaMemcpy(fpDevice_B,fpHost_B,stBytesCount,cudaMemcpyHostToDevice),__FILE__,__LINE__);
// 调用核函数
const dim3 block(32,32); // 设置block大小为2维32, 32
dim3 grid((N-1)/32 + 1,(N-1)/32 + 1); //向上取整,设置grid大小
// 预热
transpose1<<<grid, block>>>(fpDevice_A, fpDevice_B,N);
// 设置开始事件
cudaEvent_t start, stop;
ErrorCheck(cudaEventCreate(&start), __FILE__, __LINE__);
ErrorCheck(cudaEventCreate(&stop), __FILE__, __LINE__);
ErrorCheck(cudaEventRecord(start), __FILE__, __LINE__);
cudaEventQuery(start);
transpose1<<<grid, block>>>(fpDevice_A, fpDevice_B,N); //调用核函数
ErrorCheck(cudaEventRecord(stop), __FILE__, __LINE__);
ErrorCheck(cudaEventSynchronize(stop), __FILE__, __LINE__);
float elapsed_time;
ErrorCheck(cudaEventElapsedTime(&elapsed_time, start, stop), __FILE__, __LINE__);
printf("Time = %g ms.\n", elapsed_time); // 打印时间
// 将计算得到的数据从设备传给主机
ErrorCheck(cudaMemcpy(fpHost_B, fpDevice_B, stBytesCount, cudaMemcpyDeviceToHost),__FILE__,__LINE__);
// 释放主机与设备内存
free(fpHost_A);
free(fpHost_B);
ErrorCheck(cudaFree(fpDevice_A), __FILE__, __LINE__);
ErrorCheck(cudaFree(fpDevice_B), __FILE__, __LINE__);
ErrorCheck(cudaDeviceReset(), __FILE__, __LINE__);
return 0;
}共享内存
数组归约计算(例)
数组规约计算即考虑有-DUSE_DP设置精度,其运行结果(具体代码见 github )
zsh
nvcc -O3 reduce_cpu.cu -o reduce_cpu
./reduce_cpu
>>> Time = 129.05 ms.
>>> Ans: 33554432.000000zsh
nvcc -O3 -DUSE_DP reduce_cpu.cu -o reduce_cpu
./reduce_cpu
>>> Time = 69.4968 ms.
>>> Ans: 123000000.110771CPU运算情况下,其单精度下的结果完全是错误的。在仅使用全局内存的情况下设计核函数
zsh
nvcc -O3 reduce_cpu.cu -o reduce_gpu
./reduce_gpu
>>> Time = 6.23568 ms.
>>> Sum: 123633392.000000zsh
nvcc -O3 -DUSE_DP reduce_cpu.cu -o reduce_gpu
./reduce_gpu
>>> Time = 11.6348 ms.
>>> Ans: 123000000.110771仅使用全局内存的GPU运算情况下,单精度时从第四位开始有错误,且计算速度约为CPU下的11倍。
zsh
nvcc -O3 reduce_share.cu -o reduce_share
./reduce_share
>>> Time = 5.87258 ms.
>>> Ans: 123633392.000000zsh
nvcc -O3 -DUSE_DP reduce_share.cu -o reduce_share
./reduce_share
>>> Time = 12.1048 ms.
>>> Ans: 122999999.998770使用静态共享内存下GPU运算情况。考虑到全局内存的访问速度是所有内存中最低的,应减少对其使用。而寄存器是最高效的,但他只对线程可见,考虑到需要线程合作,采用线程块可见的共享内存。代码见github,一般来讲使用共享内存减少全局内存访问可以提高性能,但并不是绝对如此。但这至少带来了一个好处,现在我们的代码允许数组元素个数不是线程块大小的整数倍。
矩阵转置(例)
下面将之前的矩阵转置利用共享内存改写,
c++
// 设计核函数
__global__ void transpose1(const float *A,float *B, const int N){
const int nx = threadIdx.x + blockDim.x*blockIdx.x;
const int ny = threadIdx.y + blockDim.y*blockIdx.y;
__shared__ float S[32][33];
if (nx < N && ny < N){
S[threadIdx.y][threadIdx.x] = A[ny*N + nx]; // 合并访问,copy操作
}
__syncthreads();
const int nx2 = threadIdx.y + blockDim.x*blockIdx.x;
const int ny2 = threadIdx.x + blockDim.y*blockIdx.y;
if (nx2 < N && ny2< N){
B[nx2*N + ny2] = S[threadIdx.x][threadIdx.y]; // 调换threadIdx.x 和 threadIdx.y 使得对B的访问也是合并的
}
}通过改写核函数,使得对A,B的访问都是合并的下面几行代码极为关键,仔细体会其正确性。
c++
const int nx2 = threadIdx.y + blockDim.x*blockIdx.x;
const int ny2 = threadIdx.x + blockDim.y*blockIdx.y;
if (nx2 < N && ny2< N){
B[nx2*N + ny2] = S[threadIdx.x][threadIdx.y]; // 调换threadIdx.x 和 threadIdx.y 使得对B的访问也是合并的
}bank冲突
bank:为了获得高的内存带宽,共享内存在物理上被分为32(=wrap_size)同样宽度,可以被同时访问的内存bank,除了开普勒架构(8字节),其他架构每个bank的宽度为4字节。
共享内存数组是按照如下方式映射到内存bank中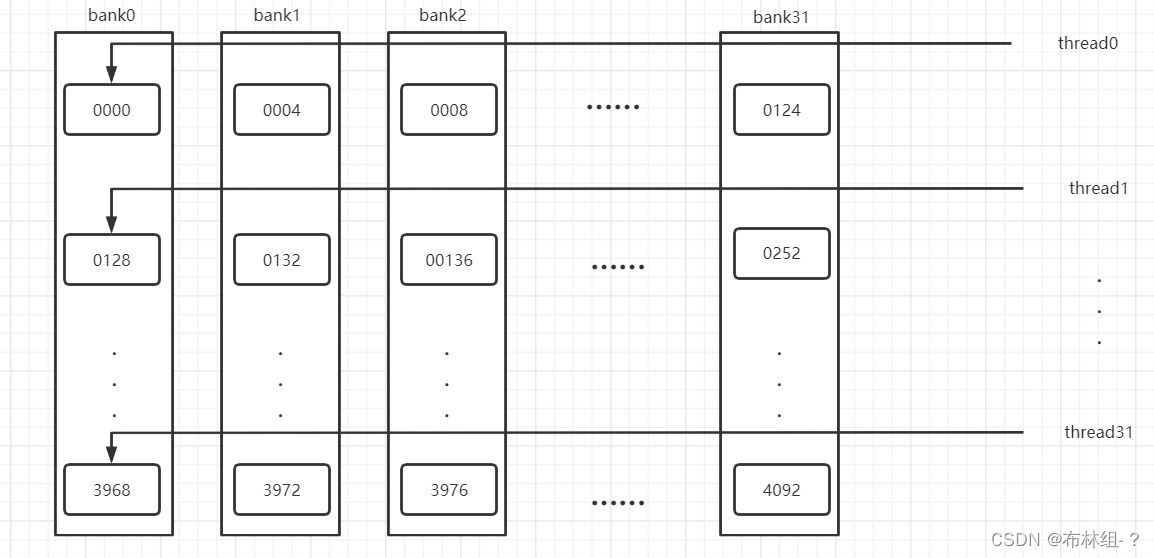 简单说来,第0到31个数组元素在32个bank的第一层,第32到63个数组元素在32个bank的第二层...
简单说来,第0到31个数组元素在32个bank的第一层,第32到63个数组元素在32个bank的第二层...
当同一个线程束内的多个线程不同时访问一个bank,此时由于不同bank可以同时访问,只需要发起一次访问请求,进行一次内存事务。但如果多个线程访问同一个bank中不同层数据,就会产生bank冲突,影响程序执行时间。
在矩阵转置代码中,如果设置__shared__ float S[32][32];,则B[nx2*N + ny2] = S[threadIdx.x][threadIdx.y]; 操作中,对于同一线程束中的线程(Idx.x连续),这32个线程恰好访问同一个bank的32个数据,发生32路bank冲突。在改变共享内存的数组大小之后__shared__ float S[32][33];,同一个线程束中的32个线程(连续的32个threadIdx.x的值)将对应共享内存数组S中跨度为33的数据,如果第一个线程访问第一个bank的第一层;第二个线程会访问第二个bank的第二层,于是这32个线程将分别访问32个不同的bank中的数据,所以没有bank冲突。
原子函数
简而言之:正如其名,原子为基本组成单元,视为不可切分的一部分。使用原子函数意味者其函数执行读——改——写操作时不会被其他线程所干扰,能够防止数据被多线程读取改写所引发的错误。
线程束基本函数与协作组
单指令——多线程
单指令——多线程意味着一个线程束中的线程只能执行一个共同的指令或者闲置,这成为单指令——多线程。
分支发散:当同一个线程束内部的线程执行条件语句的不同分支,此时造成性能下降,称之为分支发散。注意,如果一个分支不包含指令,那么即使发生分支发散也不会显著影响程序性能。
TIP
本节剩余内容不重要
伏特架构之前,一个线程束中的线程拥有同一个程序计数器,但各自有不同的寄存器状态,从而可以根据程序的逻辑判断选择不同的分支。而从伏特架构开始,引入了独立线程调度,每个线程拥有自己的程序计数器,提高了编程的灵活性,降低了移植CPU代码的难度。其代价一是增加了寄存器的负担,单个线程的程序计数器一般需要两个寄存器,也就是说,这使得SM中每个线程可用寄存器数量减少2,代价二,独立线程调度机制使得假设了线程束同步的代码变得不再安全。对于代价二,后面会介绍函数__syncwarp()线程束同步,或者生成PTX代码使用帕斯卡架构的线程调度机制: -arch=compute_60 -code=sm_89。
线程束内的线程同步函数
更多线程束内基本函数
参考CSDN ,在伏特架构以后,使用这些函数必须使用带_sync()版本,即他们会有隐式的同步功能,自动处理读-写竞争的问题。
协作组
使用协作组功能时需在相关源文件下加入#include <cooperative_groups.h>头文件,还要注意所有与协作组相关的数据类型和函数都定义在命名空间cooperative_groups下,using namespace cooperative_groups。
协作组编程模型中最基本的类型是thread_group,该类型包含以下成员函数:
void sync: 同步组内所有线程unsigned size: 返回组内总的线程数目unsigned thread_rank:返回当前调用该函数的线程在组内的标号bool is_valid:若定义的组违反了CUDA限制,返回False
线程组类型有一个成为线程块thread_block的导出类型,该类型提供了两个额外函数
dim3 group_index: 相当于blockIdxdim3 thread_index: 等价于threadIdx
另外,介绍函数tiled_partition,他可以将线程块分为设置大小的多个线程片,每一片构成一个线程组,但其size设置限制在2的整数倍不超过32的整数,例如thread_group g32 = tiled_partition(this_thread_block(),32)。
特别的,若线程组的大小在编译期间就已知,可以使用如下模板
thread_block_tile<32> g32 = tiled_partition<32>(this_thread_block())这样定义的线程组称为线程块片,线程块片额外享有如下定义的函数
unsigned __ballot_sync(int predicate)int __all_sync(int predicate)int __any_sync(int predicate)T __shfl_sync(T,v,int srcLane)T __up_sync(T,v,unsigned d)T __down_sync(T,v,unsigned d)T __xor_sync(T,v,int laneMask)
相比于普通线程束内基本函数,第一少了第一个位置的mask参数,其默认组内所有线程都参与计算,第二是洗牌少了最后一个参数,因为该宽度就是线程块片的大小。
CUDA流
概述
CUDA程序的并行层次主要有两个:核函数内部的并行,核函数外部的并行。在此之前,关注的都是内部的并行,外部并行主要指:
- 核函数计算与数据传输之间的并行
- 主机计算与数据传输之间的并行
- 不同数据传输之间并行
- 核函数计算与主机计算间并行
- 不同核函数之间并行
一个CUDA stream指的是由主机(或设备)发出的在一个设备中执行的CUDA操作,这里不考虑设备发出的流。任何CUDA操作都存在于某个CUDA流中,要么是默认流(空流),要么是明确指定的非空流,非默认流使用如下方法在主机中定义、产生和销毁
c++
cudaStream_t stream_1;
cudaStreamCreate(&stream_1);
cudaStreamDestroy(stream_1);为了检查一个CUDA流中的所有操作是否都已在设备内执行完成,CUDA运行时API提供
cudaError_t cudaStreamSynchronize(cudaStream_t stream); // 强制阻塞主机,等待CUDA流中的所有操作执行完毕
cudaError_t cudaStreamQuery(cudaStream_t stream); // 不会阻塞,仅查询默认流中重叠主机和设备计算
c++
cudaMemcpy();
cudaMemcpy();
sum<<<>>>(); // 核函数
cudaMemcpy();上述代码处于默认流中,从主机的角度看,在执行cudaMemcpy后会等待命令执行完毕,再往前走。但主机处理核函数时是异步的,即发出指令后立刻夺回控制权,但由于他们处于默认流中,下一个指令并不会立刻执行。但我们可以看到,主机发出核函数调用指令后会立刻发出下一个命令,利用这个原理,将主机计算放到核函数之后可提高性能,例如若sum_cpu与sum_gpu同等耗时。
c++
// 耗时短
sum_gpu<<<>>>();
sum_cpu();
// 耗时长
sum_cpu();
sum_gpu<<<>>>();非默认CUDA流中重叠多个核函数执行
要实现多个核函数之间的并行必须使用多个CUDA流。在使用非默认流时,核函数执行配置如下:
c++
kernel <<<N_grid,N_block,N_shared,stream_id>>>设置多流并发处理确实可以加速性能,但也要兼顾GPU的计算资源和不同架构GPU上能够并发执行的核函数个数的上限。
非默认CUDA流重叠核函数执行和数据传递
要实现核函执行与数据传输并发,必须让两个操作处于不同的非默认流。且需要使用cudaMem异步版本(同步版本下,主机发送命令后需等待传输完成),见下
c++
cudaError_t cudaMemcpyAsync ( void * dst,
const void * src,
size_t count,
enum cudaMemcpyKind kind,
cudaStream_t stream = 0
)异步传输由GPU中的DMA直接实现,不需要主机参与。
使用异步传输函数时,需要声明主机内存为不可分页内存。否则,主机内存为分页内存时,数据传输过程在使用GPU中DMA之前必须将数据从可分页内存移动到不可分页内存,从而必须与主机同步,主机无法在发出命令后立刻获得控制权,则无法实现不同CUDA流之间的并发。不可分页内存的分配可由以下两个函数的任何一个实现
cudaError_t cudaMallocHost ( void ** ptr,
size_t size
)
cudaError_t cudaHostAlloc ( void ** pHost,
size_t size,
unsigned int flags
)现在考虑主机与设备间的数据传输(H2D, D2H),例如在理想情况下,程序只需要经过三个过程, H2D,KER(设备计算),D2H,此时如果简单的将三个过程放入三个不同的流中,显然是不能得到加速,这是因为三个操作在逻辑上具有先后顺序。
要获得性能上提升,必须创造出逻辑上并行执行的CUDA操作,一种方法是将每一步CUDA操作等分为若干份。
性能提升
性能提升
事实上,分为